Measuring Implicit Human Biases
Through the Statistical Properties of Language
Racialization
ex. Thug
Happens when a word with no preexisting racial connotation comes to describe people of color asymmetrically.
Micro-aggressions
ex. Articulate
This word, specifically, works as a micro-aggression
In the US, standard linguistic varieties are ideologically associated with Whiteness and formal education
Calling a minority articulate notes surprisal at standard language usage in the absence of these traits
Covert Racism in Linguistics
Racialization occurs when regular words, with no racial connotation, become asymmetrically applied to the descriptions of actions or events of actors of color.
Covert Racialization in Sports Journalism
-
The Myth of Unbeatable Black Athleticism
Folk ideology, mistakenly applied throughout US history
Black athletes are not exceptional or naturally suited for physical activity, or for violent displays or prowess in team or individual sport
-
Black Athletes in Sports Journalism
Black athletes are described predictably differently as Exceptionality and Animalistic traits dominating the conversation
-
White Athletes in Sports Journalism
White athletes are described in predominately Leadership or Skill-based terms
The Dataset and The Procedure
Racialized SEmantics in Athletics Corpus (RSEAC)
120 Athletes
60 White; 60 Black
30 Male; 30 Female
15,500 lexemes
8.5 million total words
Combines previous methodologies
Metadata behind Sports Journalism
Highly controlled journalistic frame
Longform and event pieces, describing individuals, not teams
Variation based on patterns of actual disparities baked into the data, making racialization isolable.

Latent Semantic Analysis
Using Word Vector Models trained on the Google corpus, human participant’s results are recreated from Implicit Association Tasks.
N= Number of Subjects NT= Target Words NA= Attribute Words D = Effects Sizes P = P values
Word Vectors created from Target word stimuli and Attribute word stimuli
Collection Methods
1. Search Engine Optimization Search
➢ Search Engine Results Pages
2. Advanced Search
➢ “Serena Williams”
3. Cleaning and concatenation bash script
➢ Brings down text per article, removes noise
➢ Saves as Subcorpora
Machine Learning
Machine learning is a means to derive artificial intelligence by discovering patterns in existing data. Here, we show that applying machine learning to ordinary human language results in human-like semantic biases.
“We replicated a spectrum of known biases, as measured by the Implicit Association Test, using a widely used, purely statistical machine-learning model trained on a standard corpus of text from the World Wide Web. Our results indicate that text corpora contain recoverable and accurate imprints of our historic biases, whether morally neutral as toward insects or flowers, problematic as toward race or gender, or even simply veridical, reflecting the status quo distribution of gender with respect to careers or first names. Our methods hold promise for identifying and addressing sources of bias in culture, including technology (Caliskan et al. 2018).
Support Vector Machine—Counting Stuff
Random Forest Modeling Task—Analyzing Counted Stuff
Support Vector Machine
In machine learning, support-vector machines are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis.
This Learning Algorithm is trained to predict athlete race from lexical token counts
In this study, the subcorpora is organized by athlete
Takeaways
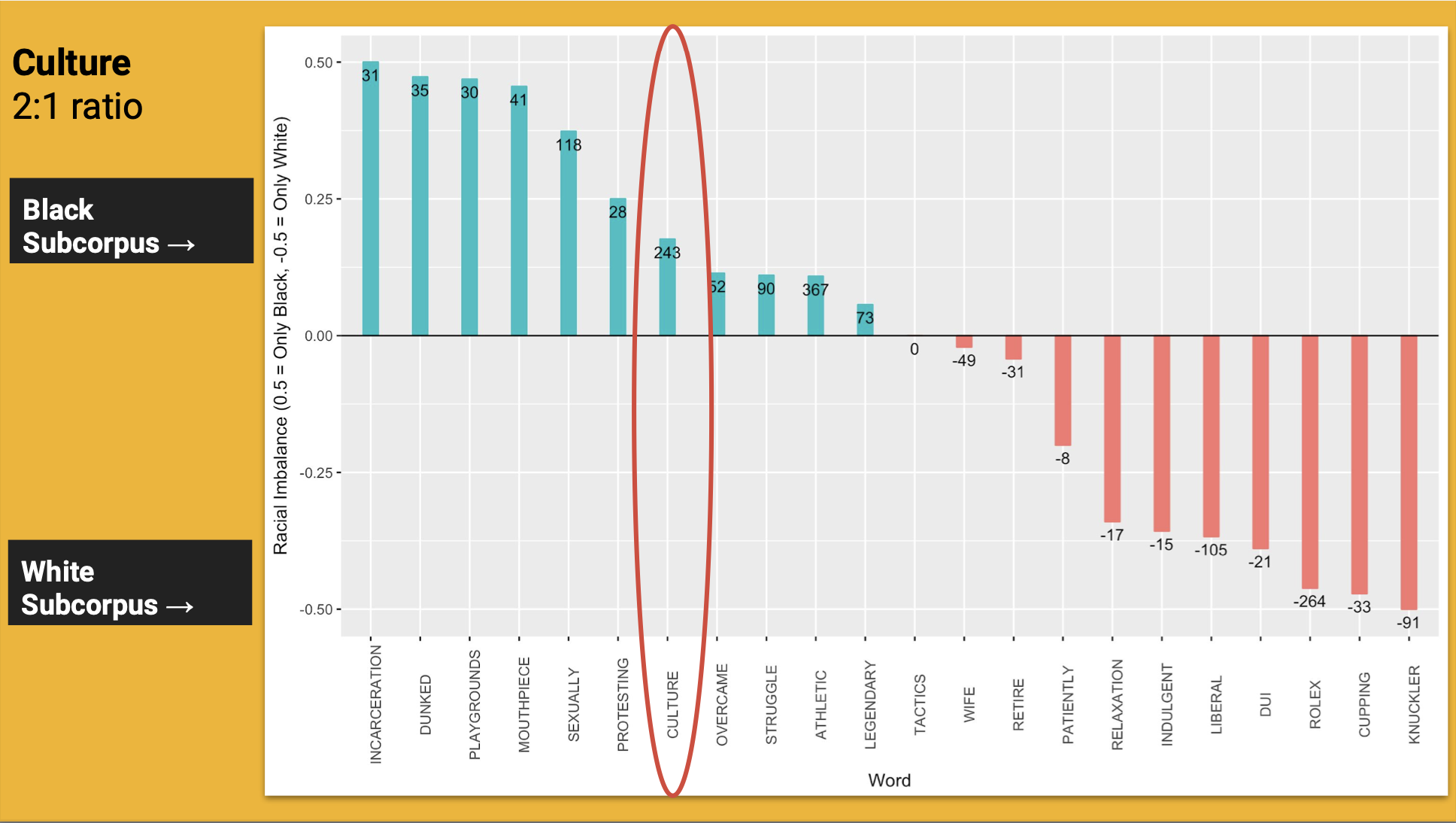
The word Culture occurs in a 2:1 ratio
Black athletes are discussed as
Infusing their own culture into the sport
Altering the sport’s culture with their ethnic presence
Culture occurrences in the White subcorpus
The culture of the sport itself, not White culture as such
Not in reference to the athlete
Two very different lexical senses of culture, the usage of which is determined by the race of the referent
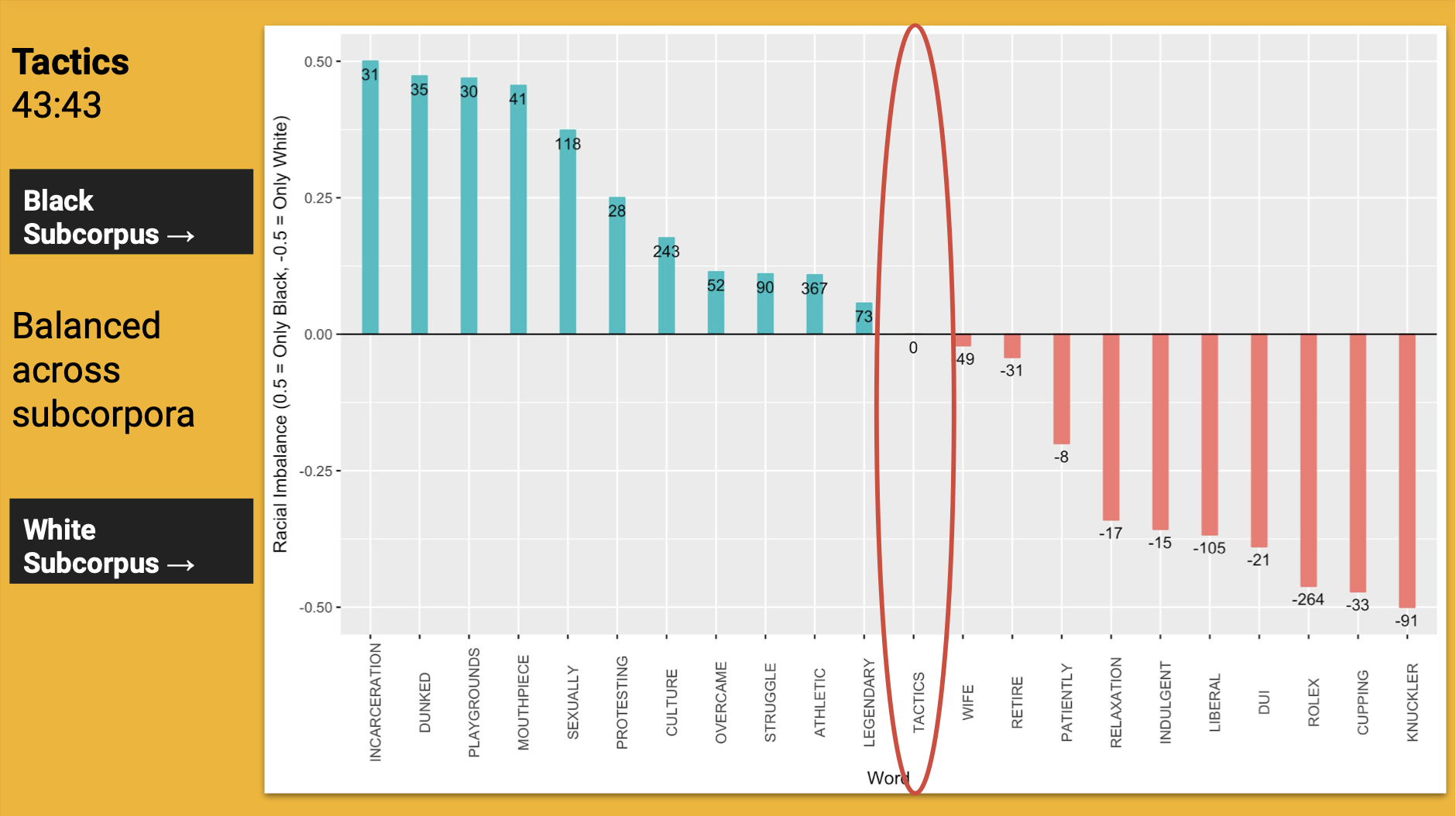
The word Tactics occurs in a 43:43 ratio
The ratio of 43:43 reveals that the word tactics was the only monitored word that showed an equality in usage among the Black and White Subcorpus.
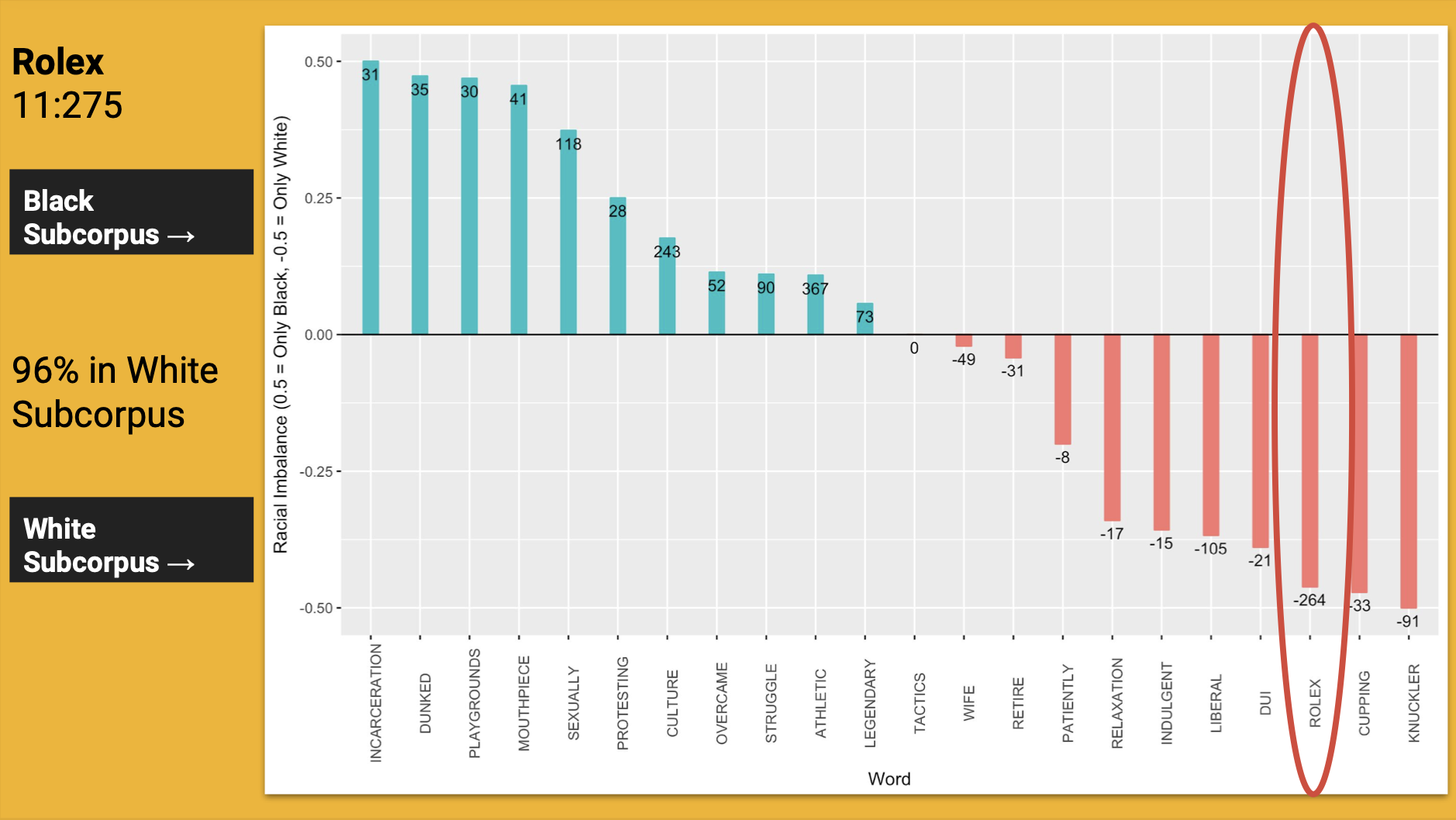
The word Rolex occurs in a 11:275 ratio
The ratio of 11:275 reveals that the word Rolex is heavily racialized, as it was much more often associated with the White athletes than the Black athletes in the sample of mainstream sports broadcasting.
In addition, it is fascinating to see a variable of class emerge as this word is so disproportionately associated with White athletes.